
A BRAND NEW VERSION OF THIS CORPUS, I.E., HURIC 2.0, IS AVAILABLE AT https://github.com/crux82/huric
THIS PAGE IS LEFT AS A DESCRIPTION OF THE OLD VERSION HURIC 1.0
HuRIC (Human Robot Interaction Corpus) is a resource that has been gathered (and is still being collected) as a collaboration between the SAG group and the Laboratory of Cognitive Cooperating Robots (Lab.Ro.Co.Co.) at Sapienza, University of Rome. The basic idea of this work is to build a corpus for Human Robot Interaction in Natural Language containing information that are yet oriented to a specific application domain, e.g. the house service robotics, but at the same time inspired by sound linguistic theories, that are by definition decoupled from such a domain. The aim is to offer a level of abstraction that is totally independent from the platform, but yet motivated by supported theories.
How to get the corpus
To download the corpus, write an email to croce@info.uniroma2.it.
- Lemmas
- Part-of-Speech tags
- Dependency trees
Every sentence has been tagged also with Frame Semantics and Holistic Spatial Semantics.
To see an example of annotation, please check the Annotation Example section.
Frame Semantics used to capture the concept of actions in Natural Language, in order to bridge between the linguistic representation of actions and robot plans or behaviours. Our semantic framework is inspired to the FrameNet corpus [cite], reporting information in terms of: Frame, conceptual structures modeling actions, events or properties (e.g. the Motion frame, representing the action of moving from one point to another in the space); Lexical Units, lexical entries (such as verbs, nouns or adjectives) that are linked and can evoke Frames in the sentences; Frame Elements, descriptors of the different elements involved in the described situation (e.g. Goal of a movement action, representing the point in the space where the movement ends). In our idea, each Semantic Frame is used to represent a possible robot plan, as well as Frame Elements can be used to instantiate a possible argument of the current plan.
Moreover robots need to perform their actions in the space, so a way to model the spatial relations as they are referred in the language is needed.
Spatial Semantics offers a model of representing the different roles and relations involved in spatial referring expressions. According to it, a Spatial Relation is composed by a Trajector, i.e. the subject of the spatial relation, a Spatial Indicator, i.e the part of a sentence holding and characterizing the nature of the whole relation, and a Landmark, i.e. the reference entity in relation to which the location or the trajectory of motion of the Trajector is specified. Spatial relation can be used to capture aspect of the spatial domain that are not exhaustively modeled by Frame Semantics. Such information can be crucial in disambiguating reference to objects in the environment (e.g. the table of the kitchen vs the table in the lounge), and thus enabling and improving the grounding process.
Corpus Details
- The Grammar Generated (GG) dataset contains sentences that have been generated by the speech recognition grammar developed for the Speaky For Robots project (S4R) , and recorded by three speakers using a push-to-talk microphone. The acquisition process took place inside a small room, thus with low background noise. Moreover, the push-to-talk mechanism helped in precisely segmenting the audio stream, and further reducing the noise.
- The S4R Experiment (S4R) dataset has been gathered in two distinct phases of the Speaky for Robots project experiment. In the first phase, the users were asked to give commands to a real robot operating in rooms set up as a real home, thus capturing all the interferences generated by talking people or sounds of other working devices nearby. The same device used for the GG dataset has been employed here for the interaction. In a second phase, the users could access a Web portal to record other commands.
- The Robocup (RC) dataset has been collected during the Robocup@Home (Wisspeintner et al., 2009) competition held in 2013, in the context of the RoCKIn3 project. The same Web portal used for the S4R dataset has been employed, and the recording took place directly in the competition venues or in a cafeteria, thus with different levels of background noise.
For the gathering and recording of the S4R and RC datasets, a web portal interface has been designed and used.
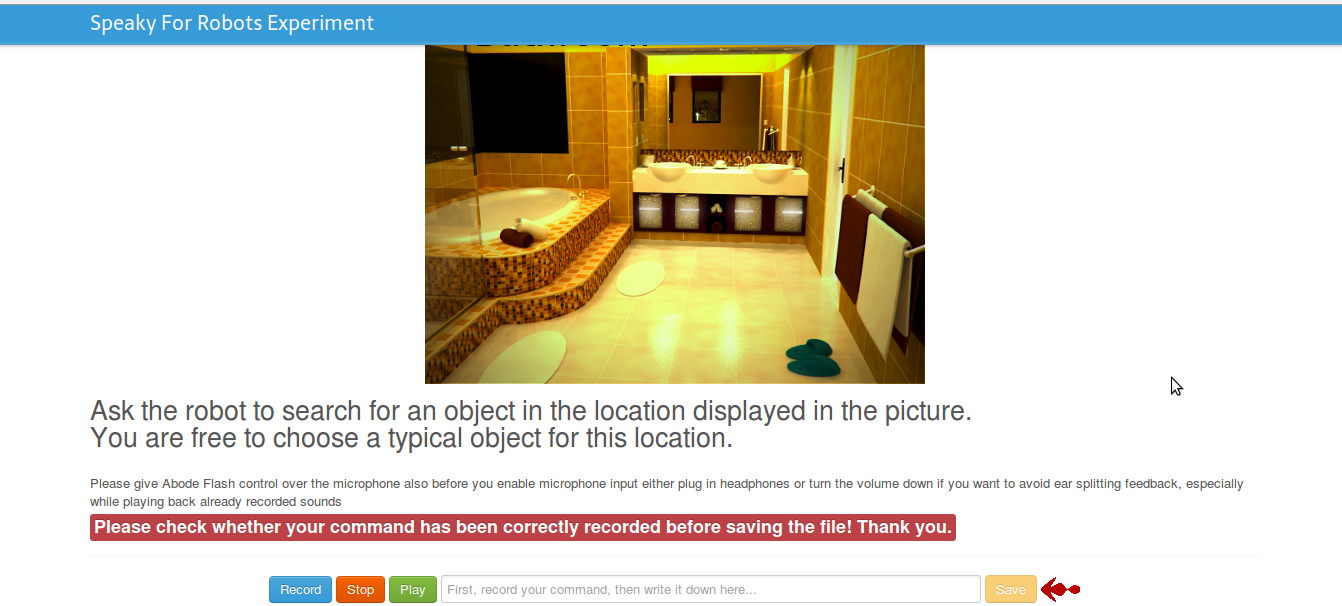
General situations involved in an interaction were described in the portal by displaying text and images. Each user was asked to give a command inherent to the depicted situation. The internal microphone of the PC running the portal has been used for recording.
The different annotation have been provided and validated through the Data Annotation Platform (showed below) by two annotators and validated by a third one. Information about the Inter Annotators Agreement can be found in [cite].
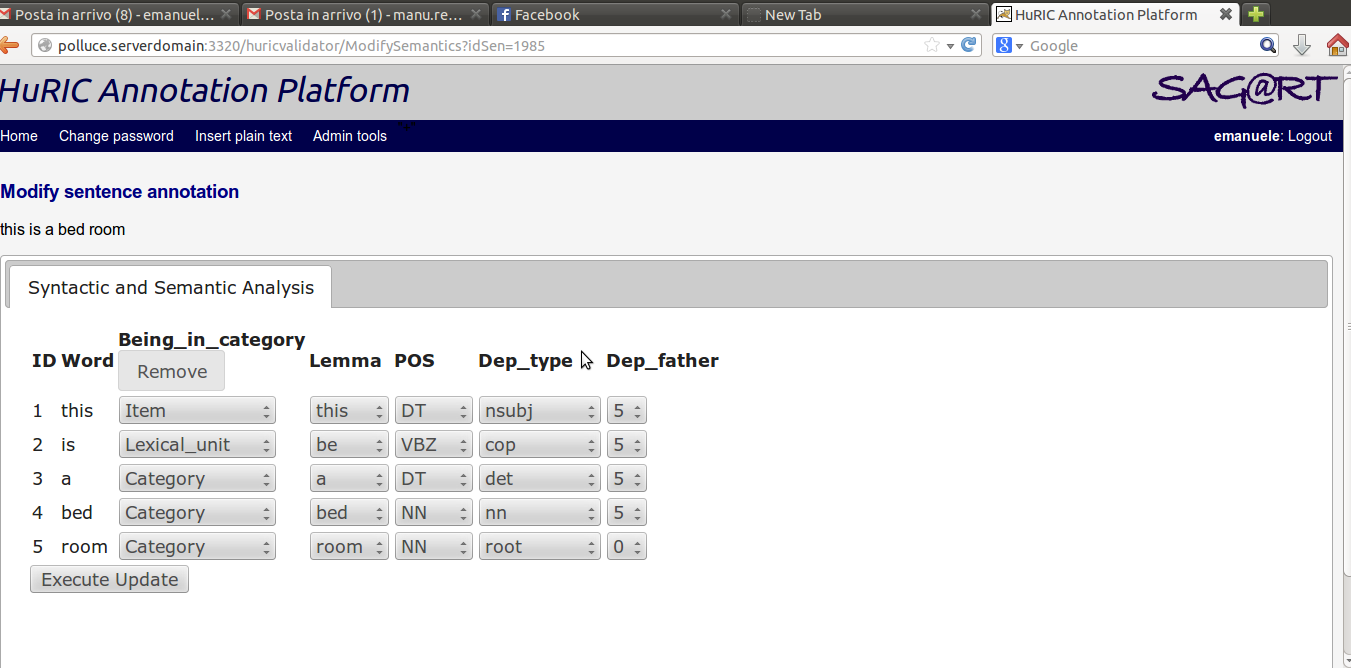
Frame Semantics and Spatial Semantics have been provided according to the motivation reported in the [link to HRI page]. While semantic annotations have been tagged directly by the annotators, morphological and syntactic information has been obtained using the Stanford CoreNLP Library [cite], and subsequently validated and corrected in the tagging phase for the semantics.
Downloads
To gain access to the corpus, please send an e-mail to the admins with your download request.
The downloadable file contains three zip file, corresponding to the three datasets. Each zip file contains two folders: in the audio_file folder all the audio files of the current dataset are contained; the xml folder contain a xml version of the annotations, following the example reported in the section Annotation Example.
Related Publications
Contacts
For more information about the corpus and the gathering methodologies please contact: