
The application of Distributional Models of Lexical Semantic allows to derive geometrical models of the meaning of the words from the analysis of large-scale corpora.
For example, our software allows to acquire the so called Word Spaces where words are described as points in a multi-dimensional space and distances reflects paradigmatic relations (such as quasi-synonymy or co-hyponymy) between words. The application of algebraic methods (such as Singolar Value Decomposition) allow to reduce the size of the acquired spaces, so improving the applicability of the resulting information in external methods and applications.
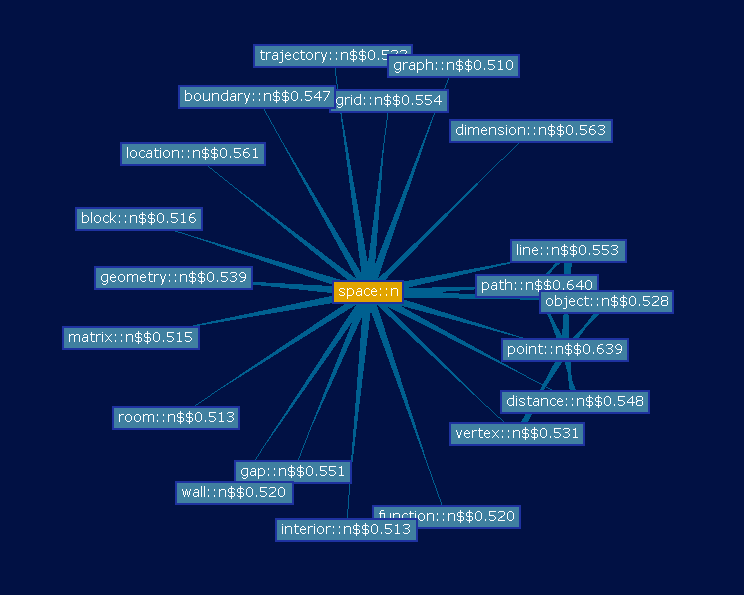
In the following images a first sight of the a Word Space derived from Wikipedia is show. In particular the most similar nouns of space and the most similar verbs of learn are shown.
More details about Distributional Models of Lexical Semantics can be found in this page.

In the context of Twitter Sentiment Analysis, we derived specific Word Spaces from Twitter large corpora. The application of Distributional Semantics techniques in this domain allows to extract new knowledge about the relations between users, hashtags, and words.
For example, in the image below the user “Matteo Renzi” is projected in the space. Red nodes in the graph are other users, related to Matteo Renzi (they are cited in the same way); brown nodes represent hashtags. Relations between hashtags and users highlight topics of interests for users.

For more information about the system and the approaches used in it feel free to contact: