This page provides a description of the Spoken Language Understanding chain for Human Robot Interaction that is the result of the collaboration between the SAG group at the University of Roma, Tor Vergata, and the Laboratory of Cognitive Cooperating Robots (Lab.Ro.Co.Co.) at Sapienza, University of Rome.
- Motivations
- The SLU Chain
- How to get the SLU Chain
- A video demonstration of the SLU Chain
- People
- Reference pages
- Related Publications
Motivations
End-to-end communication in natural language between humans and robots is challenging for the deep interaction of different cognitive abilities. For a robot to react to a user command like “take the book on the table”, a number of implicit assumptions should be met. First, at least two entities, a book and a table, must exist in the environment and the speaker must be aware of such entities. Accordingly, the robot must have access to an inner representation of the objects, e.g., an explicit map of the environment. Second, mappings from lexical references to real world entities must be developed or made available. Grounding here links symbols (e.g., words) to the corresponding perceptual information. Spoken Language Understanding (SLU) for interactive dialogue systems acquires a specific nature, when applied in Interactive Robotics.
Linguistic interactions are context-aware in the sense that both the user and the robot access and make references to the environment, i.e., entities of the real world. In the above example, “taking” is the intended action whenever a book is actually on the table, so that “the book on the table” refers to a single argument. On the contrary, the command may refer to a “bringing” action, when no book is on the table and the book and on the table correspond to different semantic roles (i.e., THEME and GOAL). Hence, robot interactions need to be grounded, as meaning depends on the state of the physical world and interpretation crucially interacts with perception, as pointed out by psycho-linguistic theories.
In (Bastianelli et al, 2016), a SLU process that integrates perceptual and linguistic information has been proposed. This process allows to produce sentence interpretations that coherently express constraints about the world (with all the entities composing it), the Robotic Platform (with all its inner representations and capabilities) and the pure linguistic level. A discriminative approach based on the Markovian formulation of Support Vector Machines is adopted, where grounded information is directly injected within the learning algorithm, showing that the integration of linguistic and perceptual knowledge improves the quality and robustness of the overall interpretation process.
The SLU Chain
The Spoken Language Understanding Chain based on the model proposed in (Bastianelli et al, 2016). This chain is fully implemented in JAVA, and is released according to a Client/Server architecture, in order to decouple the chain from the specific robotic architecture that will use it: while the Robotic Platform represents the Client, the Spoken Language Understanding Chain is the Server. The communication between these modules is realized through a simple and dedicated protocol: the chain receives as input one or more transcriptions of a spoken command and produces an interpretation that is consistent with a linguistically-justified semantic representation, coherent with the perceived environment (i.e. FrameNet).
The understanding process proposed here has the goal of producing an interpretation of an user utterance in terms of Frame Semantics, in order to give a linguistic and cognitive basis to the interpretation. Specifically, we consider the formalization adopted in the FrameNet database. According to such theory, actions expressed in user utterances can be modeled as semantic frames. These are micro-theories about real world situations, e.g. the action of taking. Each frame specifies also the set of participating entities, called frame elements, e.g., the THEME representing the object that is taken during the Taking action. For example, for the sentence
“take the book on the table′′
whose corresponding parsed version can be
[take]Taking [the book on the table]THEME
In a robotic perspective, semantic frames provide a cognitively sound bridge between the actions expressed in the language and the implementation of such actions in the robot world, namely plans and behaviors.
Sentences expressing commands are automatically analyzed by the chain by applying data driven methods trained over the Human Robot Interaction Corpus (HuRIC). This corpus contains utterances annotated with semantic predicates and paired with (possibly multiple) audio files. Utterances are annotated with linguistic information of vari- ous kinds (from morpho-syntax to semantic frames). HuRIC contains 860 audio files for 527 sentences annotated with respect to the following 16 frames: Attaching, Being_in_category, Being_located, Bringing, Change_operational_state, Closure, Entering, Following, Giving, Inspecting, Motion, Perception_active, Placing, Releasing, Searching, Taking. More info about HuRIC can be found at this link.
The SLU process has been synthesized in a processing chain based on a set of reusable components. It takes as input one or more hypothesized utterance transcriptions, depending on the employed third party Automatic Speech Recognition (ASR) engine.
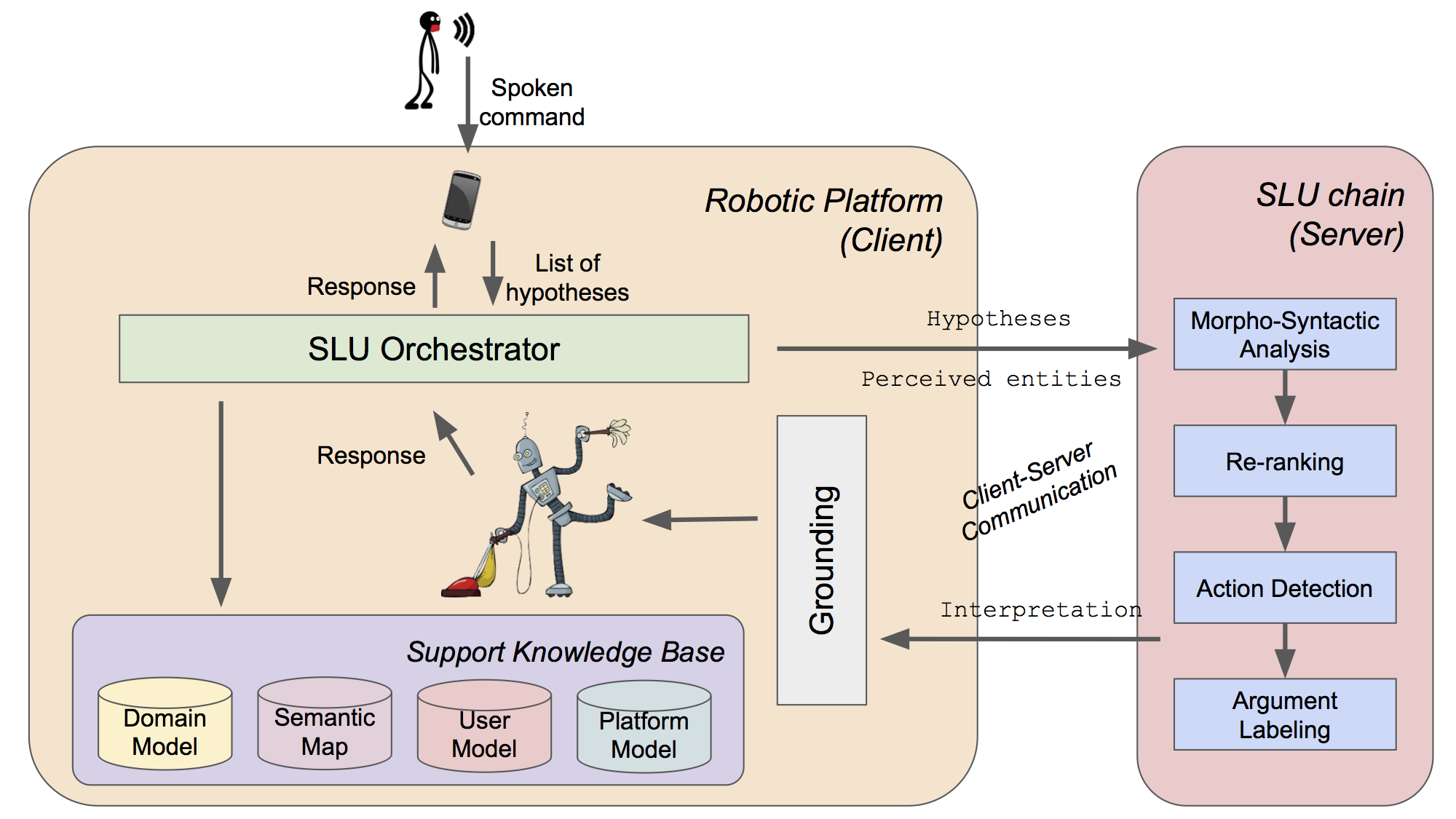
As one can see in above Figure, the chain is composed by four modules:
- Morpho-syntactic analysis is performed over every available utterance transcription, applying Part-of-Speech tagging and syntactic parsing, providing morphological and syntactic information, essential for further processing.
- If more than one transcription hypothesis is available, a Re-ranking module can be activated to evaluate a new sorting of the hypotheses, in order to get the best transcription out of the original ranking.
- The selected transcription is the input of the Action Detection (AD) component. Here all the frames evoked in a sentence are detected, according to their trigger lexical units. For example, given the above example, the AD would produce the following interpretation: [take]Taking the book on the table.
- The final step is the Argument Labeling (AL). Here a set of frame elements is retrieved for each frame detected during the AD step. Such process is, in turn, realized in two sub-steps. First, the Argument Identification (AI) aims at finding the spans of all the possible frame elements. Then, the Argument Classification (AC) assigns the suitable frame element label to each span identified during the AI, producing the following final tagging:
[take]Taking [the book on the table]THEME
For more details about the chain, please refer to (Bastianelli et al, 2016).
You can download the paper describing the SLU chain from this link.
How to get the SLU Chain
To download the SLU Chain and receive support, write an email to croce@info.uniroma2.it or vanzo@dis.uniroma1.it.
The following video shows the chain at work. You can download the video from this link.
People
Roberto Basili, Emanuele Bastianelli, Giuseppe Castellucci, Danilo Croce, Daniele Nardi, Andrea Vanzo
Reference pages
First works carried out by the SAG can be found at this link: Human Robot Interaction.
A corpus of commands for robots used to train this SLU processing chain can be found at this link: HuRIC (Human Robot Interaction Corpus).
Related Publications