This page provides a description of LU4R, the adaptive spoken Language Understanding chain For Robots tool, that is the result of the collaboration between the SAG group at the University of Roma, Tor Vergata, and the Laboratory of Cognitive Cooperating Robots (Lab.Ro.Co.Co.) at Sapienza, University of Rome.
LU4R is based on the model proposed in (Bastianelli et al, 2016). It is fully implemented in JAVA, and is released according to a Client/Server architecture, in order to decouple LU4R from the specific robotic architecture that will use it: while the Robotic Platform represents the Client, LU4R is the Server. The communication between these modules is realized through a simple and dedicated protocol: LU4R receives as input one or more transcriptions of a spoken command and produces an interpretation that is consistent with a linguistically-justified semantic representation, coherent with the perceived environment (i.e. FrameNet). In fact, the interpretation process is sensitive to different configurations of the environment (possibly synthesized through a Semantic Map or different approaches) that collect all the information about the entities populating the operating world.
- Motivations
- The Spoken Language Understanding process
- Download
- How to use LU4R
- Running LU4R
- Running LU4R ROS interface
- Running LU4R Android app
- A video demonstration of the SLU Chain
- Reference pages
- Related Publications
People
Roberto Basili, Emanuele Bastianelli, Giuseppe Castellucci, Danilo Croce, Daniele Nardi, Andrea Vanzo
Motivations
End-to-end communication between humans and robots in natural language is challenging for the deep interaction of different cognitive abilities. For a robot to react to a user command like “take the book on the table”, a number of implicit assumptions should be met. First, at least two entities, a book and a table, must exist in the environment and the speaker must be aware of such entities. Accordingly, the robot must have access to an inner representation of the objects, e.g., an explicit map of the environment. Second, mappings from lexical references to real world entities must be developed or made available. Grounding here links symbols (e.g., words) to the corresponding perceptual information. Spoken Language Understanding (SLU) for interactive dialogue systems acquires a specific nature, when applied in Interactive Robotics.
Linguistic interactions are context-aware in the sense that both the user and the robot access and make references to the environment, i.e., entities of the real world. In the above example, “taking” is the intended action whenever a book is actually on the table, so that “the book on the table” refers to a single argument. On the contrary, the command may refer to a “bringing” action, when no book is on the table and the book and on the table correspond to different semantic roles (i.e., THEME and GOAL). Hence, robot interactions need to be grounded, as meaning depends on the state of the physical world and interpretation crucially interacts with perception, as pointed out by psycho-linguistic theories.
In (Bastianelli et al, 2016), a spoken language understanding (SLU) process that integrates perceptual and linguistic information has been proposed. This process allows to produce command interpretations that coherently express constraints about the world (including the selection of all the involved entities), the Robotic Platform (with all its inner representations and capabilities) and the pure linguistic level. A discriminative approach based on the Markovian formulation of Support Vector Machines, known as SVM-HMM, is adopted, where grounded information is directly injected within the learning algorithm, showing that the integration of linguistic and perceptual knowledge improves the quality and robustness of the overall interpretation process.
The Spoken Language Understanding process
The outlined SLU process represents the engine of LU4R. It has the goal of producing an interpretation of an user utterance in terms of Frame Semantics, that guarantees a linguistic and cognitive basis to the interpretation. Specifically, we consider the formalization adopted in the FrameNet database. According to Framenet, actions expressed in user utterances can be modeled as semantic frames. These are micro-theories about real world situations, e.g. the action of taking. Each frame specifies also the set of participating entities, called frame elements, e.g., the THEME representing the object that is taken during the Taking action. For example, for the sentence
“take the book on the table′′
whose corresponding parsed version can be
[take]Taking [the book on the table]THEME
In a robotic perspective, semantic frames provide a cognitively sound bridge between the actions expressed in the language and the implementation of such actions in the robot world, namely plans and behaviors.
Sentences expressing commands are automatically
analyzed by the chain by applying data driven methods
trained over the Human Robot Interaction Corpus
(HuRIC). This corpus contains utterances
annotated with semantic predicates and paired with
(possibly multiple) audio files. Utterances are
annotated with linguistic information of various kinds
(from morpho-syntax to semantic frames). HuRIC contains
about 900 audio files for more than 600 sentences annotated with
respect to the following 18 frames:
Arriving (e.g. enter the kitchen, enter the door please, ...),
Attaching (e.g. connect to the pc on your left, disconnect from the router, ...),
Being_in_category (e.g. this is a bedroom, this is a table with a glass deck, ...),
Being_located (e.g. the fridge is on your right side, the sink is in the kitchen, ...),
Bringing (e.g. bring me yogurt from the fridge, bring the mobile to the living room, take the paper to the bathroom, ...),
Change_direction (e.g. turn left by almost 90 degrees, turn right by 60 degrees quickly, ...),
Change_operational_state (e.g. could you turn on my pc, turn on the heating, switch on the tv, ...),
Closure (e.g. close the jar, please open the pantry, ...),
Cotheme (e.g. follow me carefully, follow the guy with the blue jacket, ...),
Giving (e.g. give me one apple from the table, give me the towel, ...),
Inspecting (e.g. please inspect the kitchen, control the pocket please, check main door status, ...),
Locating (e.g. look for the glass in the bedroom, please find the glasses on the table, search for a pillow in the living room, ...),
Manipulation (e.g. grasp the box, robot please grasp the book, ...),
Motion (e.g. go to the kitchen, move to the fridge, reach the garden, ...),
Perception_active (e.g. look at me, ...),
Placing (e.g. can you place the mug to the head of the table, place the mug on the sink nearest to the refrigerator, ...),
Releasing (e.g. please release the pillow on the bed, drop the bottle in the kithcen fridge, ...),
Taking (e.g. take the phone on the left of the pc, pick up the box, catch the book, ...).
More info about HuRIC can be found at this link.
The SLU process has been synthesized in a processing chain based on a set of reusable components. It takes as input one or more hypothesized utterance transcriptions, depending on the employed third party Automatic Speech Recognition (ASR) engine.
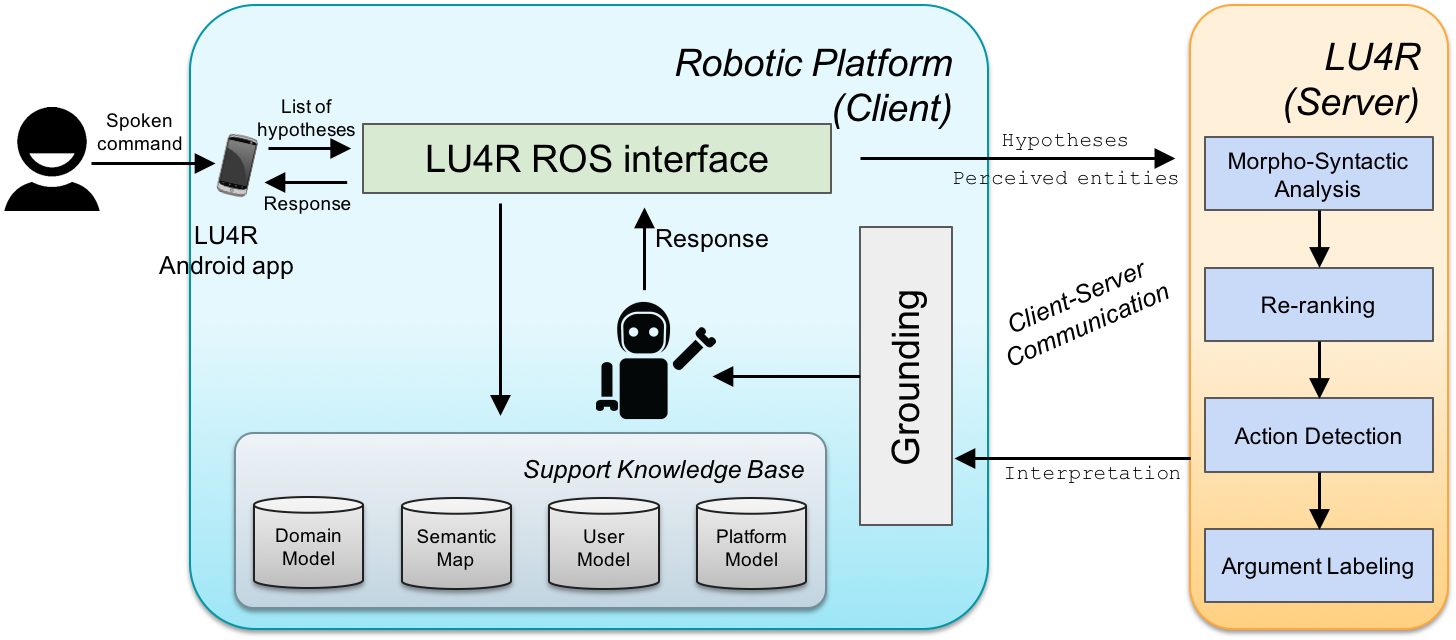 |
As one can see in above Figure, the SLU process is composed of four modules:
- Morpho-syntactic analysis is performed over every available utterance transcription, applying Part-of-Speech tagging and syntactic parsing, providing morphological and syntactic information, essential for further processing. Morpho-syntactic parsing of English sentences is here performed through the Stanford CoreNLP, version 3.4.1.
- If more than one transcription hypothesis is available, a Re-ranking module can be activated to evaluate a new sorting of the hypotheses, in order to get the best transcription out of the original ranking.
- The selected transcription is the input of the Action Detection (AD) component. Here all the frames evoked in a sentence are detected, according to their trigger lexical units. For example, given the above example, the AD would produce the following interpretation: [take]Taking the book on the table.
- The final step is the Argument Labeling (AL). Here a set of frame elements is retrieved for each frame detected during the AD step. Such process is, in turn, realized in two sub-steps. First, the Argument Identification (AI) aims at finding the spans of all the possible frame elements. Then, the Argument Classification (AC) assigns the suitable frame element label to each span identified during the AI, producing the following final tagging:
[take]Taking [the book on the table]THEME
For more details about LU4R, please refer to (Bastianelli et al, 2016) that can be downloaded from this link.
You can download the paper describing the SLU process from this link.
Download
- LU4R
- LU4R is released as a single executable jar executable. This package contains the LU4R system, pre-trained models in English for the SLU process and configuration files. It provides REST services to interact with. The dataset is composed of 527 sentences and has been used in the empirical investigation in (Bastianelli et al, 2016).
- Download the latest version (Version 0.2.1). Requires Java 1.8+.
- LU4R ROS interface
- This package contains the ROS node. It is an orchestrator between the robot, the Android application and LU4R. It communicates with the Android application, acting as a Server. Once the list of transcriptions is received from the Android app, it is forwarded to LU4R.
- Checkout the code from
https://github.com/andreavanzo/lu4r_ros_interface(Version 0.1.0) - LU4R Android app
- It is a simple Android application that allows to:
(i) send to the ROS node the list of transcriptions for a
given spoken command (through the Google Speech APIs) and
(ii) move the robotic platform through a virtual joypad
(the ROS node publishes on
/cmd_vel). - Download the latest version (Version 0.1.1)
If you are in trouble with LU4R and you are interested in receiving support, write an email to croce@info.uniroma2.it or vanzo@dis.uniroma1.it.
In this section, a short tutorial for the complete usage of LU4R is presented.
java -jar -Xmx1G lu4r-x.x.x.jar [type] [output] [lang] [port]
where:
[type]is the LU4R operating mode,basicorsimple. Thebasicsetting does not contemplate perceptual knowledge during the interpretation process. Conversely, thesimpleconfiguration relies on perceptual information, enabling a context-sensitive interpretation of the command at the predicate level.[output]is the preferred output format of the interpretation. The available formats are:xml: this is the default output format. The interpretation is given in the XDG format (eXtended Dependency Graph) and XML compliant container (see Basili and Zanzotto, 2002). Notice that the LU4R ROS interface features methods for easy extraction of the interpreted predicates directly from an XDG.amr: the interpretation is given in the Abstract Meaning Representation.conll: it is a CoNLL-like tabular representation of the predicates found.[lang]: the operating language of LU4R. At the moment, only theen(English) version is supported.[port]: the listening port of LU4R.
The startup process is completed once the message
Server launched: listening on port [port]
is prompted.
For example, the command
java -Xmx1G lu4r-0.1.0.jar simple amr en 9090
launches the perceptual chain (
simple
) in English (
en
) on the port
9090
and returns the interpretation in AMR format (
amr
).
Once the service has been initialized, it is possible to
start asking for interpreting user utterances. The server
thus waits for messages carrying the utterance transcriptions
to be parsed. Each sentence here corresponds to a speech
recognition hypothesis. Hence, it can be paired with the
corresponding transcription confidence score, useful in the
re-ranking phase. The body of the message must then contain
the list of hypotheses encoded as a JSON array called
hypotheses
, where each entry is a
transcription
paired with a
confidence
according to the following syntax:
{"hypotheses":[
{"transcription":"take the book on the table",
"confidence":"0.9",
"rank":"1"},
...,
{"transcription":"did the book on the table",
"confidence":"0.2",
"rank":"5"}
]
}
where:
transcriptionis the text corresponding to the spoken utterance;confidenceis the confidence value provided by the ASR;rankis the ranking position among the hypotheses list.
Additionally, when the
simple
configuration is selected, it requires the list of entities
populating the environment the robot is operating into, in
order to enable in order to enable the interpretation process that
depends on the environment. Notice that if the
entity list is empty, the
simple
SLU process operates as the
basic
one. This additional information must be passed as the
entities
parameter in the following JSON format:
{"entities":[
{"atom":"book1",
"type":"book",
"preferredLexicalReference":"book",
"alternativeLexicalReferences":["volume","manual",...],
"coordinate":{
"x":"13.0",
"y":"6.5",
"z":"3.5",
"angle":"3.5"}},
...
{"atom":"table1",
"type":"table",
"preferredLexicalReference":"table",
"alternativeLexicalReferences":["bar","counter","desk","board"],
"coordinate":{
"x":"12.0",
"y":"8.5",
"z":"0.0",
"angle":"1.6"}}
]
}
where:
atomis a unique identifier of the entity;typerepresents the class of the entity (e.g. book, table,...);preferredLexicalReferenceis the preferred word used to refer to that particular entity;alternativeLexicalReferenceis a list of alternative words used to refer to the entity;coordinaterepresents the position the entity, in terms of planar coordinates (`x`,`y`), elevation (`z`) and `angle` is the orientation.
The above parameters are described in details in the README file provided with LU4R.
The service can be invoked with a HTTP POST request that puts together the hypo and entities JSONs as follows:
http://IP_ADDRESS:PORT/service/nlu
POST parameters: hypo={"hypotheses":[...]}
entities={"entities":[...]}
Additional examples, that show how to invoke the chain from a
BASH command-line, are reported and described in the README file provided with the chain.
lu4r_ros_interface
in your
catkin_ws/src
folder. Then, runroscore
to start the ROS master. The ROS node can be finally launched through the following command:
rosrun lu4r_ros_interface android_interface _port:=[port] _lu4r_ip:=[lu4r_ip_address] _lu4r_port:=[lu4r_port] _semantic_map:=[semantic_map]
where:
_port: the listening port of the LU4R ROS interface. This is required by the Android app, enabling a TCP connection between them._lu4r_ip_address: the ip address of LU4R. If the LU4R and the LU4R ROS interface are on the same machine, ignore this argument._lu4r_port: the listening port of LU4R._semantic_map: the semantic map to be employed, among the ones available intosemantic_maps. The semantic maps are in JSON format, and represent the configuration of the environment (e.g., objects, locations,...) in which the robot is operating. Whenever asimpleconfiguration of LU4R is chosen, the interpretation process is sensitive to different semantic maps.
The Android app enable the ASR through the Google Speech APIs. It is provided as an Android application package (APK) file, to be installed on an Android smartphone or tablet (requires Android 5+).
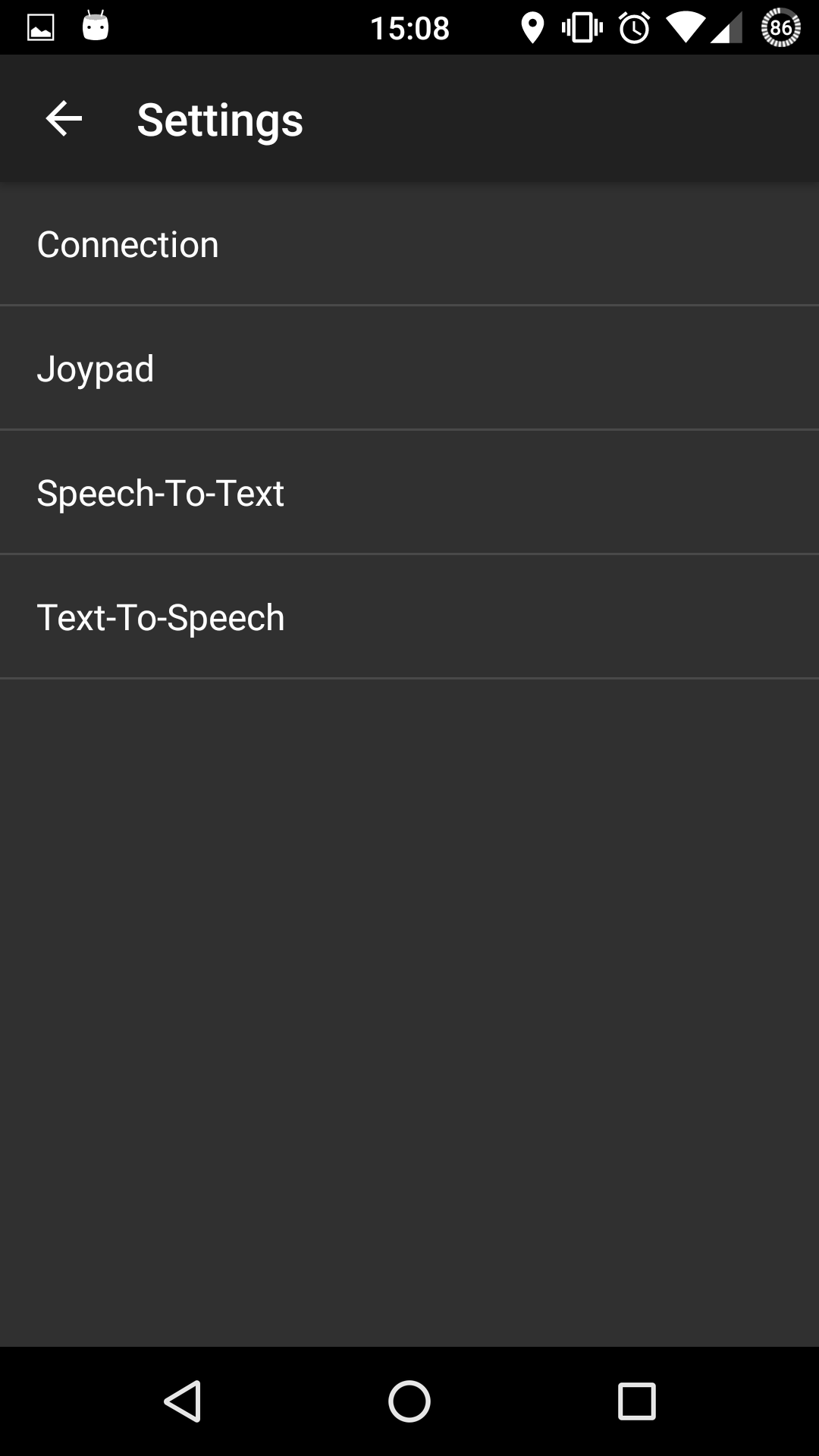
 |
- Connection: everything concerning the connection parameters. The IP address must be the same assigned to the machine running LU4R ROS node. The port is the one set up for the LU4R ROS node server.
- Joypad: everything concerning the virtual joypad configuration.
- Speech-To-Text: configuration of the ASR engine.
- Text-To-Speech: configuration of the TTS engine.
 |
 |
In the home screen, a right-swipe open the menu, showing the different operating modalities. Speech Interface is the panel in charge of sending the hypothesized transcription to LU4R ROS node.
 |
 |
 |
The following video shows LU4R at work. You can download the video from this link.
Reference pages
First works carried out by the SAG can be found at this link: Human Robot Interaction.
A corpus of commands for robots used to train this SLU processing chain can be found at this link: HuRIC (Human Robot Interaction Corpus).
Related Publications